会自学的最强阿尔法狗诞生 突破人类思维束缚
2017/10/19

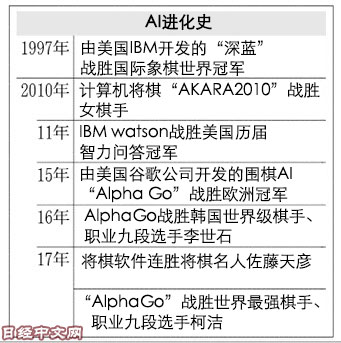
美国谷歌旗下的英国子公司沉思科技(DeepMind Technologies)日前开发出了新版本围棋用人工智能(AI)“AlphaGo Zero”。此前的AlphaGo在击败全球顶级棋手时通过学习约3千万专业棋手的对弈数据使自身变得强大。但AlphaGo Zero无需人类作出示范,也能反复与自己对弈,借助自学创造出胜率最高的下法。
以前的AlphaGo对人类就已经具有压倒性优势,棋力达到史上最强。这种实力有助于将来在产业方面得到应用,例如通过大量数据自动找到调整电力供需的时机等。
英国科学杂志《自然》杂志10月19日发表了相关文章。谷歌仅向AlphaGo Zero 教授了围棋规则。AlphaGo Zero 将现有的2种学习方法结合起来,分别通过2种方法思考下一手,还能对彼此思考出的结果进行参照。
 |
| 柯洁与AlphaGo对弈(KYODO) |
AlphaGo Zero最初是随机落子,但通过反复与自己对弈,迅速提高水平。在进行实验3天后,面对2016年3月击败顶级棋手李世石时的旧版AlphaGo取得了100战全胜。
人类在多年的围棋历史中不断自主完善了被称为“定式”的惯用下法。在试验40天后,AlphaGo Zero已经与自己对弈 2900万局,强大程度超过2016年5月时面对全球最强棋手柯洁九段取得3连胜的AlphaGo版本。据称,AlphaGo Zero还开始掌握人类未知的下法。
美国围棋协会主席安迪·奥肯等在发给《自然》杂志的稿件中指出,“AlphaGo Zero在中盘阶段的若干判断简直就像迷一样”。另一方面,随着人工智能和人类在下棋时总结出了相同的定式,证明“人类长达数个世纪的围棋活动取得的成果并非全部错误”。
沉思科技的首席执行官杰米斯·哈萨比斯在AlphaGo击败最强人类棋手时表示,“这是最后一次和人类对弈”。为达成“完全不依赖人类的人工智能”这个目标,哈萨比斯在此后继续对AlphaGo进行了改进。
此前,人工智能曾将人类的对弈数据作为“教师”加以学习。因此有观点指出,人工智能虽然强大,但仅仅处于人类知识的延长线上。沉思科技通过让人工智能从零开始自学,采用被称为“没有教师的学习”方式,创造出了不受人类思维束缚的革新性人工智能。
 |
版权声明:日本经济新闻社版权所有,未经授权不得转载或部分复制,违者必究。
报道评论





